原文:http://www.w3.org/DesignIssues/Semantic.html
蒂姆伯.纳斯李
日期:1998年9月。 最后更新:$日期:1998/10/14 20点17分13秒$
现状:尝试给出语义万维网体系结构的高级计划。 编辑状态:草案。
欢迎评论
Semantic Web Road map 语义网路线图
一个为未来设计的路线图,一个除实验思想外未经过任何测试的架构计划。
它被要求从一个20000英尺的高度来编写,作为未来web设计路线图必须的一部分。它从架构的概览中拆分出来作为一个独立的部分且还需要更多的阐述而不是概述。
必然的,从一个20000英尺的高度,大的事物也会只有一个小的提及。它是一个架构,然而,在这个情形下,事物怎样按照希望的那样组合到一起,所以我们应该认识到它将进行缓慢的变化,这是一个变化的文档。
这个文档是一个计划,为实现一个web上数据互相连接的应用集合。并以这种方式形成一个一致的逻辑数据的web(语义网)。
Introduction 简介
web被设计为信息空间,它的目标不仅仅是对人与人之间的交流有用,同时机器应该也能够参与进来并起到帮助作用。对此一个主要的障碍是现实中大多数 web上的信息专门提供给人们使用,即使它是由数据库驱动并有很好定义的方式(最起码在一定条件下)。数据的结构对一个浏览网页的机器人来说是不明显的。 撇开把机器训练得像人一样行动的人工智能问题,the Semantic Web approach instead develops languages for expressing information in a machine processable form(语义网致力于替代在一个机器过程形式中表达信息的开发语言).
这个文档给出一个路线图-一个增长的技术介绍序列(sequence),它将带我们,一步步从今天的web到一个由机器推理并到处存在且极具威力的web.
它紧跟Web的架构记录(note),其为已完成的数据定义存在的设计决议和原则.
机器能理解的信息:语义网
语义网是数据的web,在某些情况下就像全球的数据库。创建这样一个基础下部结构的基本原理随处可见[web未来讲话&C]这里仅仅描述我所理解的架构??
The basic assertion model 基本的声明模型
当看一个可能的统一web语义声明的算法,最低限度要求者需要的原则是它要基于一个非常通用的普通模型。仅当这个通用的模型生成任何预期的应用都能被映射的模型。这个生成模型就是Resource Description Framework(资源描述框架).
见:RDF Model and Syntax Specification
一般来说,这非常简单。简单到对模型本身你没有什么事情你能做除了堆叠很多东西在顶层。基本的模型仅仅包含一个声明(assertion)的观念,和一个 引用(quotation)的观念-做一个声明的声明。介绍这个是因为它以后将在任何地方都有需要且大多初始的RDF应用都是与数据(“元数据”)相关的 数据,在这里声明的声明是基础.即使是在逻辑之前(因为对目标应用的RDF而言,声明是一些资源描述的一部分,那些资源是一个隐含参数而声明作为一个资源 的属性).
就数学的发展而言,语言在这一点上没有否定或暗示,因此它的作用是有限的.给出一个事实的集合,对与一个给出的问题很容易说出一个证据是否存在,因为既不是这些事实也不是这些问题能有足够作用使得问题难以解决。
在这个层次上的应用有很多.大多的applications for the representation of metadata(表示元数据的应用)在这个水平上能被RDF来操控.例子包括卡片索引信息(the Dublin Core),私密信息(P3P),文档的关联样式表,知识产权标记(???)和PICS标记(照片分类).我们在这里讨论表示型数据,它简单而典型:因为 没有语言用来解释查询或推论规则.
RDF文档(documents)在这个层次上并没有巨大的威力.and sometimes it is less than evident why one should bother to map an application in RDF.答案是我们希望得到这个数据,有时候在一个应用中它是有限且简单的.之后,和其他应用的数据组合再进入web.运行在整个web的应用必须能够使 用一个通用的框架用来从所有其他应用中组合信息.例如:访问控制逻辑可能使用一个组合密码,组成员资格和数据类型信息来进行明确的允许访问或拒绝访问.查 询可能允许威力巨大的逻辑表达式关联到来自域名的私有的数据,且这些数据的表示语言并不是很有表现力的.这份文档的目的是展示部分可能已经发展了的计划. (???)
The Schema Layer 架构(模式)层
RDF的基本模型允许我们在黑板上做很多事情,但却没有给我们很多工具.它给了我们一个声明和引用的模型,在模型上我们能够以任意新的格式来映射数据.
下一步我们需要一个Schema层来声明已经存在的新的属性.同时我需要多说几句(??).我们希望能够约束它使用的方式.典型地,我们想要约束它能应用 对象(object)的类型.这些元声明使得在一个文档做基本的检查成为可能.就像在SGML中”DTD”允许检查元素是否被用在适当的位置,因此在 RDF的Schema允许我们去检查,例如,一个开车人的驾照上有一个人的名字,而不是一个车的模型作为它的名字.
哪些原始的东西要介绍,更有作用的语言能被定义到这样层次还是下一层次,这些对我来说不是完全清楚的.在这个领域现在有一个RDF Schema工作组(RDF Schema working group).Schema语言对合法的组合作简易的声明. 如果SGML DTD用来作为模板,schema能够用在一个威力有限的语言中.在这个schema语言中约束很容易扩散到更具威力的逻辑表达式层(下一层结构),但在 这里我们为了限制能力,不这样做。例如:一个人可以说在一个schema中一个属性foo是唯一的,扩散后,对任意的x,如果y是x的foo,并且z是x 的foo,那么y等于z.这要使用在这一层上并不可用的逻辑表达式.但是只要schema语言由专门schema引擎来操控,而不是一个通用的推理引擎来 操控,那就没问题.
当我们用一种语言来处理这类事情-当然我认为这将会很常见-我们必须注意这种语言要有着良好逻辑定义。然后,我们可能想要在逻辑层写一些能理解schema语言语义的接口,并把它和其他逻辑信息组合到一起.
Conversion language 转化语言
一个命名空间工作的可演化性需求是必须和普通RDF的知识在同一层次上,能够根据规则将一个RDF schema中的文档(document)转换到另一个RDF schama当中(大概对如何处理有一个天生的理解).
根据最小能力原则,该语言可以在没有否定的情况下使用隐含关联(推论规则)(这似乎是一个好的特征,当事实上一个人能够很容易地写出一个规则来从另一个声 明B的一个声明A中定义推论,这实际上是假的,即使该语言没有一个实际的方式来表示”False”.无论如何,形式上该语言没有足够的必要去写一个驳论, 来方便一些人.紧接着,尽管这个语言更具表现力,我们不是依赖固有的能力去构造一个矛盾的声明,但是在应用上特别的限制详细文档的表现力.Schemas 提供一个方便的地方来描述那些限制条件.)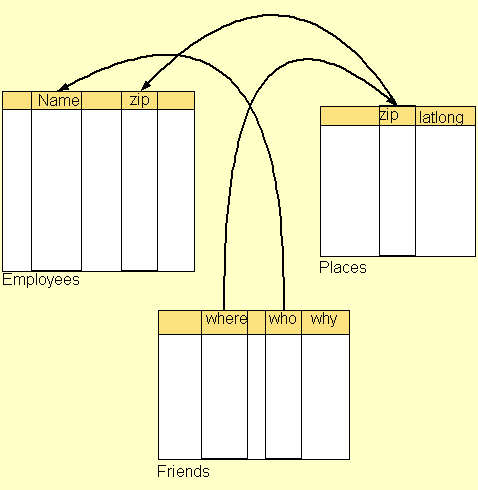
一个应用程序的例子,这一层当2个数据库被语义的链接连接,独立地构建然后被放到web上,且其允许在一个上面queries转换到另一个queries 上面.在这里,有人注意到”where”在friends表和”zip”在places表示同一个意思.另一些人注意到”zip”在places表 和”zip”在employees表中表示同一个事物,因此就像箭头表示的那样.给出这个信息,搜索任何一个employee名字叫Fred,zip为 02139能够扩展employees让其包含friends.所有的这些需要一些RDF的”equivalent”属性.
The logical layer 逻辑层
紧接着,下一层是逻辑层.我们需要一些方法将逻辑写入到文档中来允许这样的事情,例如,从一个文档的另一个类型规定文档的一个类型的一个推论;一个 文档违反了自我约束规则的检查;一个把不知道的术语转化为知道的术语的query方案.假定我们已经在语言中有了引用,下一层应是谓词逻辑 (not,and,等等)再下一层是量化(quantification)(对所有的x,y(x)).
RDF的应用程序在这一层次上基本是很有限的仅仅靠的是想象.一个这一层次的简单例子是:当有两个数据库,互相独立,然后放到web上,再由语义的 links连接,它允许在一个上面的queries转化为另一上面的queries.Many things which may have seemed to have needed a new language become suddenly simply a question of writing down the right RDF.当你有一个语言,其在对引用进行谓词演算方面有着超强的能力的时候,你需要为这个特定的应用定义一个心的语言,有两件事情要做:
一个是必须选定(限定)推理引擎的功能,接收器必须有,且定义一个能够被理解的完整RDF的子集;
一个是可能需要定义一些简单的功能在文档集合中的约束语言里有效率地传输表达式(One will probably want to define some abbreviated functions to efficiently transmit expressions within the set of documents within the constrained language. )
如果有疑问,见:
What the Semantic Web is not - 常见问题解答
下面的metro map展示了语义网里面的key循环.在web部分,在左边,展示了URI是什么,使用HTTP,转入一个文档的表示层作为一些MIME类型的bits字 符.它然后解析到XML再进入RDF,来生成一个RDF图,或在逻辑层,生成一个逻辑表达式.在右手边,语义的部分,展示了RDF图怎样包含这个URI的 一个引用.来自key的依赖,和文档里面包含的声明相结合,可以导致一个语义的web引擎解除另一个URI的引用.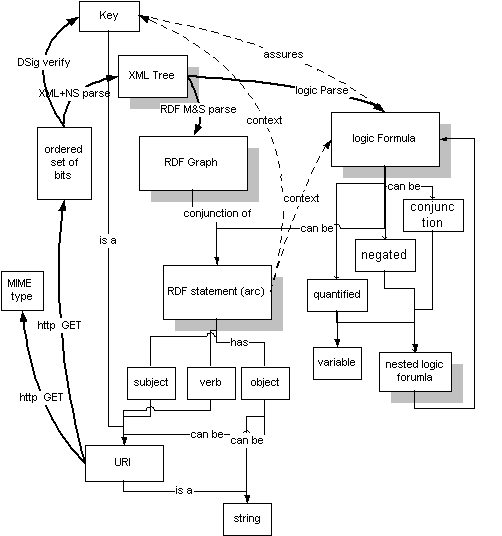
Proof Validation - a language for proof 验证校验 - 校验语言
RDF模型没有讲到推理引擎的形式,并且它是一个明显的问题,as there is no definitively perfect algorithm for answering questions - or, basically, finding proofs.眼下在语义网的开发里面,尽管,我们没有处理那个问题.大多数应用依照一些清晰的约束规则构建验证,并且所有其他部分需要做这个通用的验 证.这是很平常的.
例如,当一个人被允许访问一个网站,他们能够给出一个文件来向web服务器解释为什么他们有使用权.验证将会成为声明(assertions)和推 理规则的链(chain)[well,DAG]with pointers to all the supporting material.
同样的,事务(transactions)涉及到隐私信息,还有许多的电子商务.该文件通过网络发送将被写入一个完整的语言.然而,他们将会被约 束,因此,如果是queries,结果是可计算的,且在大多数情况下它们将会是proofs(验证),HTTP”GET”将包含一个客户端有权限去响应的 验证.这个响应将有一个其本身是不是确实是被问到的问题的验证.
Evolution rules Language 演化规则语言
RDF在逻辑层已经有能力去表达推理规则.例如,你应该能够说这样的事情”如果X机构的zipcode(邮政编码)是y,那么x的work- zipcode是y”.就像上面记录的,使用remarks(附注)来分散web,到最后将会很有趣.但在这简短的条款中不会产生可重复的结果除非我们限 制documents(文档)的表现来解决独有的应用问题.
两个基本的功能我们需要RDF引擎来完成:
1.对一个版本为n的实现要能够读取足够的RDF schema并能推断出怎么样读取版本为n+1的文档.
2.对独立于B类型应用且发展成熟的A类应用,它应该有相同或是相似的功能来读取和处理足够的schema信息,来处理来自B应用的数据.
(见evolvability article)
RDF逻辑层作为一种语言对建立推理规则来说是足够的.注意它没有address(记录,标记)任何特别的推理引擎的heuristics(启发式过程/ 探索性的方法或过程)它是一个开放的领域通过语义网将会使其更加开放且富有成果(which which is an open field made all the more open and fruitful by the Semantic Web).换句话说,RDF将允许你写一些规则但不会告诉任何人在这个阶段哪个规则作用于他们.
例如,a library of congress schema talks of an “author”,和一个英国图书馆谈话的”创建者”,a small bit of RDF将能够说对任何人X和任何资源y,如果x是y的(LoC)作者,那么x是y的(BL)创建者.这是一类的规则,它可以用来处理可展开的问题.哪里有 一个处理器来找到它?在这个案例中其要找到版本为2的文档,然后这个版本为2的文档且要去找到规则去转化它并进入版本为1的文档,然后这个版本为2的 schema将自然地包含或指向这个规则.在这个案例中的可追溯文档材料的两个独立创建的schemas(In the case of retrospective documentation of the relationship between two independently invented schemas),然后理所当然的,规则的指针能够添加到任何一个schema中,但如果那不(社会化)具有实用性,那么我们有另一个注解问题的例子.这 问题第三方索引能够解决,其能够搜索两个schemata之间的连接(connections).在实践的过程中,搜索引擎提供这项功能是很有效率地-你 将只需要问搜索引擎一个schema的所有关联并检查规则的结果哪些像这两个.
Query languages 查询语言
还有一个查询语言.一个query可以被认为是一个返回的关于结果的断言(A query can be thought of as an assertion about the result to be returned).根本地,在任何情况下RDF在逻辑层足够去表现这个.然而,在实践中一个query引擎有特定的算法和索引能确定哪个起作用,并能回 答特定类别的query.
它可能在实践中开发一个词汇表,在以下两种方式中的任意一种中起到帮助:
1.它允许普通能力的query类型能够用较少页面的数学运算来简洁地表达,或
2.它允许包含约束的queries被表达,这很有趣因为它们包含可计算的属性.
SQL是都进行实现的一个例子.
将query语言定义到RDF逻辑的条款中明显是很重要的.例如,查询一个服务器上的一个资源的作者,one would ask for an assertion of the form “x is the author of p1” for some x.请求一个所有作者的限定list.将会找到一个作者的集合,这样任何作者都在这个集合里面,并且每个人在这个集合都是一个作者.如此等等.
在实践中,web上搜索引擎算法差异,和proof-finding 算法在pre-web逻辑系统建议语义网中应该有许多形式的代理来为不同形式的query提供答案.
One useful step the specification of specific query engines for for example searches to a finite level of depth in a specified subset of the Web (such as a web site).当然对不同的场景可能有几个可选的(结果).
另一个metastep是query引擎描述语言的规范–基本上一个query集合的规范这个引擎能以一个普通的方式返回.This would open the door to agents chaining together searches and inference across many intermediate engines.
Digital Signature 数字签名
公共密钥密码学是一个非凡的科技它完全改变了什么是可能的.当一个人能添加一个数字签名块作为一个已存在文档的修饰,尝试去给推理系统添加信任(trust)的逻辑通常受到系统的限制.由于能给帐号添加信任,通用的逻辑模块需要扩展来包含已签名的声明的key.
就像所有的逻辑,这个的基本原理,一开始可能不是十分吸引人除非我们看到建立在它上层的东西.这个基础部分是keys的介绍,其作为一级类别的objects(在那里URI能够作为一个公共key的字面值),和一个普通推理关于keys的声明属性的介绍.
在一个实现中,这意味着那个推理引擎将需要绑定到签名验证系统.文档将被解析不仅仅进入到声明树,但会进入到关于谁签名了哪个声明的声明树.对推理规则来说,验证校验将检查逻辑,但对于声明一个文档已经签名了,会检查签名.
结果将会是一个系统,其能够通过整个范围的基于安全和信任系统的public-key表达和推论关系.
当RDF对存在验证语言层发展成熟数字签名就变得有趣了,在许多地方它可以和RDF并行发展.
在W3C,进入数字签名工作来自许多方向,包含DSig1.0签署”pics”标签,还有各种各样的数位签署的文件的submissions.
Indexes of terms 条款索引
现给出一个全球的语义网声明,当前的搜索引擎技术(1998)应用与HTML页面将可能转化到索引而不是单词.但其由RDF 对象(objects)组成.这将允许更加高效的web搜索好像它是一个巨大的数据库,而不是一个巨大的书.
现在碰到版本A转化到版本B的需求,因此当两个数据库存在大批的(可能是虚拟的)RDF文件,甚至是初始的schemas可能没有一样的,一个关于它们等值的可追溯文档材料将允许一个搜索引擎通过跨数据库搜索来满足queries.
Engines of the Future 未来的引擎
当搜索引擎索引HTML页面找到许多搜索答案并覆盖大部分的web网络,然后它会返回许多不适合的答案.这样的搜索结果是没有”准确性”可言的.形 成对比的,逻辑引擎典型特点是能够通过限制输出来确定哪个是可验证的正确答案,但遭受通过搜索大量纠缠的数据去构造有效的答案的低效.”组合爆炸式搜索” (combinatorial explosion)的可能性跟踪起来已经相当棘手.
然而,规模(scale)上,哪个搜索引擎已经成功可能促使我们去重新检查我们的设想.如果一个未来的引擎将一个推理引擎和一个搜索引擎结合.它可以给出 两者(两个世界)中的最好(结果),and actually be able to construct proofs in a certain number of cases of very real impact.它将延伸到索引(indexs),而索引包含一个给出条款的所有事件的完整列表(lists),然后使用逻辑排除无用的indexs,留下 可以用来解决给出的问题的部分.
因此,没有东西会使得”组合式爆炸”(combinatorial explosion)消失,许多现实生活中的问题能通过几步推理就能够在原始的web上解决,the rest of the reasoning being in a realm in which proofs are give,或者有一些约束(constrains)能很好地理解可计算的算法.我同样期望一些(string)商业的刺激来开发引擎和算法,这将有效地解 决具体类型的问题.这可能涉及到生成和今天的搜索引擎的索引(indexs)非常类似的中间结果缓存.
尽管仍然没有一个机器能够保证能回到任意的问题,回答实际问题的能力在我们日常生活尤其是商业活动中或许已经相当出色了.
在这个系列:
- What the Semantic Web is not - 回答一些常见的值得怀疑的问题.
- Evolvability: 语言的性质技术的演进
- Web Architecture from 50,000 feet
References 参考文献
The CYC Representation Language
Knowledge Interchange Format (KIF)
@@
致谢
这个计划基于和W3C团队,W3C成员公司的商讨.同样感谢MIT/LCS(美国麻省理工学院计算机实验室)的 David Karger 和 Daniel Jackson.